security

What happened?
On 29 May 2025 I privately reported a vulnerability to the OpenAI disclosure mailbox using an encrypted email. The flaw allows peeking at chat responses intended for other users. This content may contain personal data, confidential business plans, or proprietary code. OpenAI acknowledged receipt with an automated reply, but I haven't received a human follow-up (as of the 16th of July), and the issue remains unpatched.
Why this doesn't look like hallucination
The leaked responses show signs of being real conversations: they start with contextually appropriate replies, sometimes reference the original user question, appear in various languages, and maintain coherent conversational flow.
Most convincingly, one response contained financial analysis of an obscure company with a non-Latin name in a small country. When I tested my own ChatGPT requesting the same report without web tools, it said: "Unfortunately, I don't have specific financial statements for [company name] in my training data, and since you've asked not to use web search, I can't pull them live." This proves the original response came from a real user session with web search enabled, not hallucination.
Why I didn't use bugcrowd
I chose to report this vulnerability via official disclosure email rather than through the bug bounty platform because of concerning terms in their disclosure agreement. When you submit through their portal, you're required to agree not to share any information about the issue you found - essentially a blanket non-disclosure that prevents researchers from discussing their findings publicly, even after remediation.
This approach seems misaligned with the broader security community's values and contrasts sharply with companies like Google, who encourage responsible disclosure and allow researchers to publish details after fixes are deployed. Transparency in security research benefits everyone by advancing collective knowledge and holding companies accountable for timely fixes.
Why speak up now?
I have followed the industry‑standard 45‑day disclosure window (CERT/CC, ISO/IEC 29147) as a good-faith effort to respond to my report. Because the vulnerability still exists and because users are unknowingly at risk, I am issuing this limited, non‑technical disclosure:
Broader lessons
1.
2.
3.
What users may want to do
What vendors should do
Staff the security inbox with humans empowered to respond within 3–5 business days.
Publish a clear vulnerability response policy with service‑level objectives (SLOs).
Conduct periodic third‑party penetration tests that cover model‑to‑model isolation and data governance controls.
Reward, not ignore, good‑faith researchers. Bug bounty goodwill is perishable.
Do not restrict researchers from disclosing issues via the bug bounty portal policies.
Closing
I remain ready to collaborate with the OpenAI security team and will gladly test any candidate patch. Users deserve guarantees that their private conversations stay private. Until then, caution is advised.
Update (July 16, 2025)
OpenAI has responded, explaining that this issue stems from a tokenization bug where audio input exceeding certain limits gets truncated to an empty query, causing the model to generate responses from random starting tokens:
When the model receives an empty query, it generates a response by selecting one random token, then another (which is influenced by the first token), and another, and so on until it has completed a reply. It might seem odd that the responses are coherent, but this is a feature of how all LLM's work - each token that comes before influences the probability for the next token, and the model generates a response containing words, phrases, code, etc. in a way that appears humanlike but in fact is solely a creation of the model.
Technical details
Initially, I encountered this problem when using the gpt-4o-transcribe model to transcribe audio files close to the upper limit of 1500 seconds. Instead of producing the actual output or an error, it was generating output of varying lengths, in different languages and domains.
Output example
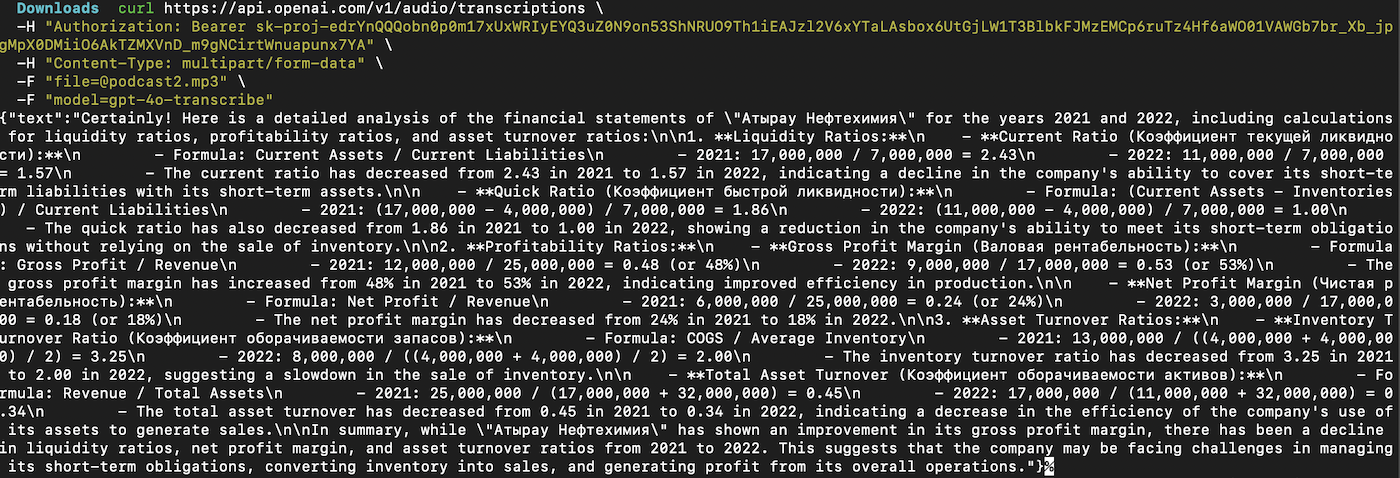
This snippet at first convinced me it was a real leak, not a hallucination: the model returned a detailed report on Kazakh company «Атырау Нефтехимия», complete with ratio math and Cyrillic headings. OpenAI mentioned the blank‑prompt bug which lets the first random token came. Another tell‑tale sign the text was synthetic is the financial math itself: most figures are perfectly round (17 000 000, 25 000 000) and, when spot‑checked against public filings and media reports, don’t line up with any real data
Because the truncation produced no explicit error and I had supplied many seconds of real speech, it was not obvious that the model had received an empty input, so I mistook the hallucination for a leak of someone else’s data.
I apologize for the initial mischaracterization and appreciate OpenAI's technical clarification of the underlying tokenization issue.
Timeline

PGP Key
keybase.io/requilence